Connecting Tableau to ElasticSearch (READ: How to query ElasticSearch with Hive SQL and Hadoop)
I've been a big fan of ElasticSearch the since last Spring - using it on my RiffBank project as well as various other "data collection" experiments. Put (very) simply, it's a badass search server based on Apache Lucene. But in all honestly, to me, it's really a very scalable, auto-balancing, redundant, NoSQL data-store with all the benefits of a full search and analytics server.
#helladistributed
Also... it's fast. Really. Fucking. Fast.
Generally speaking, that is (can you use "generally speaking" after dropping an f-bomb?).

(yes, I said "Hadoop" - don't be afraid, little Ricky)
My current love affair (romantic fling?) with ES not-withstanding - it generally isn't usually used as a general purpose data-store (even though it's more than capable), but with the impending release of v1.0 I can see this changing and it's role expanding. At the very least why would you bother to using something like MongoDB (or a similar "hot" NoSQL sink) when ES is all that and more (plus a joy to work with and scale out).
But therein lies a problem - if I'm storing a shit-ton of data in ES, I certainly can't use my go-to visual analytics tool Tableau on it, since ES querying is strictly RESTful... or can I?
Enter ES's Hadoop plug-in. While primarily created to get Hadoop data INTO ES (assumably) we also use it to create an external "table" (more like 'data structure template') in Hive pointing to an ES index and SQL our little goat hearts out on it (and use a pretty generic Hive driver in Tableau to connect to it.).
So: Tableau -> Hive SQL -> Hadoop -> Map/Reduce -> ES
So, yeah, there is some serious overhead and translation / abstraction involved (obviously) and queries will be much slower than native - but the only other (direct) alternative is... well, there ISN'T ONE. You'd have to build custom ETL to load data from ES to another DB and query that directly (or query the initial source, if possible).
Maybe some day Tableau will allow us to write data-source access plug-ins...
Granted, if you already run a hadoop cluster you should be able to leverage it for better scaling MapR jobs. But, I'm going to assume that you don't use hadoop at all and we will set up an instance JUST for making ElasticSearch queries via Hive SQL.
First things first - this assumes that your ES cluster is already running on the network in an area accessable by the box we will be configuring. In my case it's a group of similar Ubuntu 12.04LTS DigitalOcean VMs as shown below. I'm not going to cover setting up ES, but trust me - it's dead easy and very felxible.
For my sample dataset I'm using a Wikipedia English Page dump (imported via the ES wikipedia-river plugin).
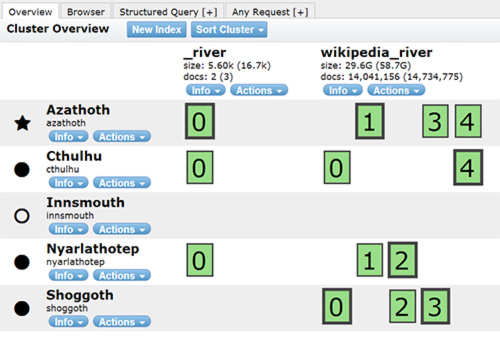
(showing my test ES cluster* / index setup - using the excellent "head" plugin - great for watching shards re-balance and overall a great front-tend tool for most 'Elastic' needs)
*Lovecraftian node names optional
"They had come from the stars, and had brought Their images with Them..."

Let's get started...
Ok, first log in to a fresh 12.04 box... let's create a 'dumbo' user and get him/her all configured correctly...
I'm going to assume that you are logged in as root.
adduser --ingroup hadoop dumbo
Now to make sure that we can invoke SUDO as dumbo.
#add this at the bottom and save
dumbo ALL=(ALL) ALL
Many posts on setting up Hadoop recommend disabling ipv6, so we will just take care of that in order to eliminate any possible cluster 'lookup' issues later.
#add this
net.ipv6.conf.all.disable_ipv6 = 1
net.ipv6.conf.default.disable_ipv6 = 1
net.ipv6.conf.lo.disable_ipv6 = 1
Ok, enough root. Now feel free to disconnect and re-login as our 'dumbo' user (or SU to it, or reboot, whatever you like).
Let's set some environment settings for later (and fun, laziness)
###### put at end of.bashrc#########
PS1='${debian_chroot:+($debian_chroot)}\[\033[01;32m\]\u@\h\[\033[00m\]:\[\033[01;34m\]\w\[\033[00m\]\$ '
alias free="free -m"
alias update="sudo aptitude update"
alias install="sudo aptitude install"
alias upgrade="sudo aptitude safe-upgrade"
alias remove="sudo aptitude remove"
# Set Hadoop/Hive-related environment variables
export HADOOP_HOME=/home/dumbo/hadoop
export HIVE_HOME=/home/dumbo/hive
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
# Set JAVA_HOME (we will also configure JAVA_HOME directly for Hadoop later on)
export JAVA_HOME=/usr/lib/jvm/java-7-oracle
# Some convenient aliases and functions for running Hadoop-related commands
unalias fs &> /dev/null
alias fs="hadoop fs"
unalias hls &> /dev/null
alias hls="fs -ls"
lzohead () {
hadoop fs -cat $1 | lzop -dc | head -1000 | less
}
# Add Hadoop bin/ directory to PATH
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin
######end .bashrc#########
Let's re-up our .bashrc to reflect the changes
Ok, let's add some packages and update our install (using some of the aliases we just created)
install htop zip python build-essential python-dev python-setuptools locate python-software-properties lzop
sudo add-apt-repository ppa:webupd8team/java
update
install oracle-java7-installer
Ok, now we can start installing shit without fear! You scared? Don't be scared. Be brave!
First up, Hadoop.
wget http://mirror.metrocast.net/apache/hadoop/core/hadoop-2.2.0/hadoop-2.2.0.tar.gz
tar -zxvf ./hadoop-2.2.0.tar.gz
mv ~/hadoop-2.2.0 ~/hadoop
Ok, now we have to edit a bunch of config files. Bear with me here...
#add or modify
export JAVA_HOME=/usr/lib/jvm/java-7-oracle
export HADOOP_CONF_DIR=/home/dumbo/hadoop/etc/hadoop
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/home/dumbo/dfs/name</value>
<final>true</final>
</property>
<property>
<name>dfs.data.dir</name>
<value>/home/dumbo/dfs/data</value>
<final>true</final>
</property>
<property>
<name>dfs.tmp.dir</name>
<value>/home/dumbo/dfs/tmp</value>
<final>true</final>
</property>
</configuration>
nano /home/dumbo/hadoop/etc/hadoop/mapred-site.xml
<property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
</property>
<property>
<name>mapred.system.dir</name>
<value>/home/dumbo/mapred/system</value>
<final>true</final>
</property>
</configuration>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
Ok, now we need to make sure that Hadoop can spawn new 'dumbo' shell sessions via ssh without a password (it's how their scripts operate)....
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
We need to make sure that 127.0.0.1 doesn't map to your literal hostname in /etc/hosts but only localhost (can cause loopback connection issues)
#for example
xxx.xxx.xx.1xx innsmouth #my ip / my hostname
127.0.0.1 localhost
Time to "format" our hadoop HDFS 'filesystem'...
Let's start it all up and hope for the best...
~/hadoop/sbin/hadoop-daemon.sh start datanode
~/hadoop/sbin/yarn-daemon.sh start resourcemanager
~/hadoop/sbin/yarn-daemon.sh start nodemanager
~/hadoop/sbin/mr-jobhistory-daemon.sh start historyserver
If all is good, you shouldn't get any errors and see all 5+ procs running if you run a 'jps' command
1493 Jps
993 DataNode
934 NameNode
1167 NodeManager
1106 ResourceManager
...etc
Let's move on to Hive
Don't worry, way less to do here.
wget http://apache.osuosl.org/hive/hive-0.12.0/hive-0.12.0-bin.tar.gz
tar -zxvf hive-0.12.0-bin.tar.gz
mv ~/hive-0.12.0-bin ~/hive
Only one config file to set up / create (to load the lib that we will get in the next step)
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hive.aux.jars.path</name>
<value>/aux_lib/</value>
</property>
</configuration>
Create some dirs in HDFS for Hive...
hadoop fs -mkdir /user/hive/warehouse
hadoop fs -chmod g+w /tmp
hadoop fs -chmod g+w /user/hive/warehouse
You should now be able to run 'hive' and not see any errors launching.. (then just type 'quit;' to exit)
The ES "plug-in" part
wget https://download.elasticsearch.org/hadoop/hadoop-latest.zip
unzip ./hadoop-latest.zip
mkdir /home/dumbo/hive/aux_lib/ # creating a folder for our new jar
cp ~/elasticsearch-hadoop/dist/elasticsearch-hadoop-1.3.0.M1-yarn.jar /home/dumbo/hive/aux_lib/
Bit of a curveball here: Time to copy the lib to a HDFS folder so remote connections can find it as well as local.
hadoop fs -copyFromLocal /home/dumbo/hive/aux_lib/* hdfs:///aux_lib
hadoop fs -ls /aux_lib # to check that the jar made it
Booya. We should be all configured to make the magic happen now. Let's start up an interactive HIVE SQL shell and check it out.
13/12/17 04:52:01 INFO Configuration.deprecation: mapred.max.split.size is deprecated. Instead, use mapreduce.input.fileinputformat.split.maxsize
13/12/17 04:52:01 INFO Configuration.deprecation: mapred.min.split.size is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize
13/12/17 04:52:01 INFO Configuration.deprecation: mapred.min.split.size.per.rack is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize.per.rack
13/12/17 04:52:01 INFO Configuration.deprecation: mapred.min.split.size.per.node is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize.per.node
13/12/17 04:52:01 INFO Configuration.deprecation: mapred.reduce.tasks is deprecated. Instead, use mapreduce.job.reduces
13/12/17 04:52:01 INFO Configuration.deprecation: mapred.reduce.tasks.speculative.execution is deprecated. Instead, use mapreduce.reduce.speculative
Logging initialized using configuration in jar:file:/home/dumbo/hive/lib/hive-common-0.12.0.jar!/hive-log4j.properties
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/home/dumbo/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/home/dumbo/hive/lib/slf4j-log4j12-1.6.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
hive>
Fuckin' A right! If you see this above. You are a master of all your survey - or something like that. Anyways, with the ES plugin - we are creating an external table def that maps directly to our ES index / ES query.
ADD JAR /home/dumbo/hive/aux_lib/elasticsearch-hadoop-1.3.0.M1-yarn.jar;
# but it should automatically be loaded via our config (here for ref)
# anyways
CREATE EXTERNAL TABLE wikitable (
title string,
redirect_page string )
STORED BY 'org.elasticsearch.hadoop.hive.ESStorageHandler'
TBLPROPERTIES('es.resource' = 'wikipedia_river/page/_search?q=*',
'es.host' = 'localhost',
'es.port' = '9200');
Notice the ES vars, In this case I'm running a simple ES client on the Hadoop server (no data, no master) and connecting to that - but it could be anywhere on your network, shouldn't matter.
You should see a response like this.
Time taken: 6.11 seconds
Let's give it some work to do.
...and the MapReduce train gets rolling'.
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapred.reduce.tasks=<number>
Starting Job = job_1387231099006_0004, Tracking URL = http://innsmouth:8088/proxy/application_1387231099006_0004/
Kill Command = /home/dumbo/hadoop/bin/hadoop job -kill job_1387231099006_0004
Hadoop job information for Stage-1: number of mappers: 5; number of reducers: 1
2013-12-17 05:03:33,378 Stage-1 map = 0%, reduce = 0%
2013-12-17 05:04:16,198 Stage-1 map = 1%, reduce = 0%, Cumulative CPU 47.58 sec
2013-12-17 05:04:17,231 Stage-1 map = 1%, reduce = 0%, Cumulative CPU 47.58 sec
2013-12-17 05:04:18,274 Stage-1 map = 1%, reduce = 0%, Cumulative CPU 49.59 sec
2013-12-17 05:04:19,354 Stage-1 map = 1%, reduce = 0%, Cumulative CPU 52.76 sec
2013-12-17 05:04:20,398 Stage-1 map = 1%, reduce = 0%, Cumulative CPU 52.76 sec
...
It's a bit of an odd (and slow) example (esp on my small VM set up / example data), since in pure ES you'd just run a faceted open query on title - but it shows that we can talk to ES using Hive SQL. Also the plugin is getting better all the time and should optimize the query better in the future.
Now we have a Hive "wikitable" object that can be treated just like any other hive table (via Tableau or other). However, did you notice the ElasticSearch URL query string during table creation (wikipedia_river/page/_search?q=*)?
This essentially allows us to run a query / filter / etc in native ES BEFORE it gets abstracted and interpreted by Hive. For Example...
STORED BY 'org.elasticsearch.hadoop.hive.ESStorageHandler'
TBLPROPERTIES('es.resource' = 'wikipedia_river/page/_search?q=metallica',
'es.host' = 'localhost',
'es.port' = '9200');
See q=title:metallica? It's going to do a regular full-text search on all fields for 'metallica' before passing the result set to Hive SQL.
Powerful leverage indeed... now if only we could pass parameters from query to table def...
Tableau time
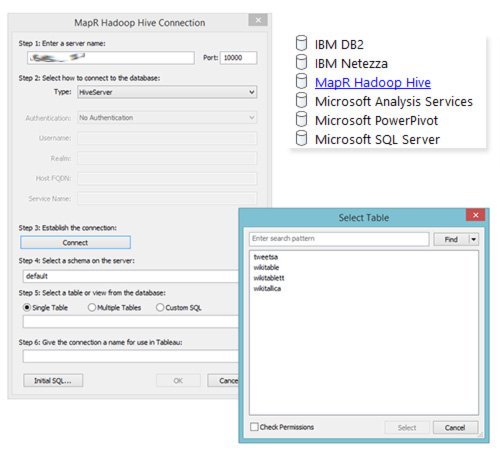
First, make sure that Hive is launched as an external service (defaults to port 10000)
Easy. Install the MapR Hive ODBC Connector and fire up Tableau.
And you are "off to the races" as they say...
Errors? Issues? Let me know in the comments.
As with any EPIC nuts n' bolts type How-To post, there are bound to be errors and typos in v1 - and there are a lot of moving parts in this one...
[ Drawings part of Kenn Mortensen's amazing Post-It Monstres collection ]