RiffBank – Parsing arbitrary Text-based Guitar Tab into an Indexable and Queryable “RiffCode for ElasticSearch
- Part 0: Why Guitar Tab?
- Part 1: Text Tab to "RiffCode" (this post)
- Part 2: Riff Storage and Querying in ElasticSearch
- Part 3: Simple UI display with PHP-FatFree and Twitter Bootstrap
Guitar tablature is meant for human readability...
not for machine consumption.
Granted it's "procedural" and "linear" already, but it's also column-based AND row-based at the same time (readers read down a short row and then over) - you are dealing with text chunks that are easily understandable by a human, but require a lot of "context" and rules for a machine to decipher. Not to mention the fact that it's hand-written by humans, which is another error waiting to happen.
Aside from the "how to do this" aspect, I also had to create a system to 'normalize' tab into a consistent format that lent itself to being queried properly.
The solution? "RiffCode"
My initial implementation goes like this:
- encode single notes and chords into "pseudo-words"
- turn those riff sections into "sentences"
- capture note meta-data when possible (palm-muting, etc)
By storing the data this way I can use full-text search technology to try and gleam results from (which, with ElasticSearch, worked quite well).
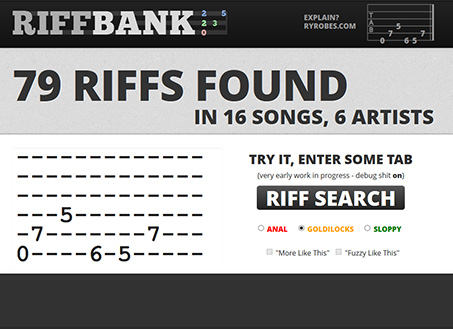
In practice it looks / works like this:
input
B-|----------------------------------------------------------------|
G-|*--------------------------------------------------------------*|
D-|*-----------------------------------------------5--------------*|
A-|---7-7-5-7---------7-7-5-----------7-7-5-7------5---------------|
E-|-0---------------0-------7-6-5---0--------------3---6-5-0-3-5---|
output
The concept is to pivot each "column line" of tab and keep it as "lossless" as possible (including extraneous spaces) using a basic letter system for fret number and number for strings. The system has some shortcomings (over 26 frets), but is adequate (if not damn good) for 95% of tab.
Ok, now how do we do this a million times over? - Python.
Since I wasn't even sure this was going to work - I wrote fast and carelessly. So what we have is a very inelegant solution that iterates over the text several times and creates several dictionaries - and then re-constructs it at the end.
It's one cluster fuck of a text-parsing function, but it works, and it's fast enough.
"No time for love, Dr. Jones!"
riff_number = 0
commonchar = None
string_line = None
lineresults = {} # or dict()
for lineno, linestr in enumerate(x):
linestr = linestr.rstrip('\r\n') #.strip()
first3char = linestr[0:3]
if len(linestr) > 0: # not counting some common accent symbols in case tab author was crazy w solo accents
prev_commonchar = commonchar
mod_linestr = linestr.replace('~',' ').replace('\\',' ').replace('^',' ' )
commonchar = (collections.Counter(mod_linestr).most_common(1)[0])[0] # [0] is digit, [1] is freq
if commonchar == ' ':
try:
commonchar = (collections.Counter(mod_linestr).most_common(2)[1])[0] # [0] is digit, [1] is freq
except:
pass # ? not sure see 2x4
else:
prev_commonchar = commonchar
commonchar = 'DIVIDER'
# find (probable) string lines and label them
if (commonchar == '-' and linestr.find('P') < 0) or (commonchar.isdigit() and linestr.find('-') > 0): # so we don't grab the Palm Mute line...
if string_line == None:
prev_string_line = string_line
string_line = 1
else:
prev_string_line = string_line
string_line = string_line + 1
#lineresults[lineno] = string_line
else:
prev_string_line = string_line
string_line = None
# find (probable) meta / PM line ?
if linestr.find('P') > 2 and string_line == None:
prev_string_line = string_line
string_line = 0
# find (possible) section headers
if len(linestr)<30 and commonchar.isalpha() and string_line == None and commonchar <> 'DIVIDER':
riff_name = 'riff name?'
else:
riff_name = None
#print "line number: " + str(lineno) + ": " + linestr.rstrip()+' ',
#print '{' + commonchar + ' ' + str(string_line) + ' ' + str(riff_name) +'} Rnum' + str(riff_number) #+ 'prevst'+str(prev_string_line)
if prev_string_line == 6:
riff_number = riff_number + 1
elif (commonchar == 'DIVIDER' and prev_string_line < 6 and prev_string_line > None):
riff_number = riff_number + 1
# add all this shit to a dick(t)
if not lineresults.has_key(riff_number):
lineresults[riff_number] = {}
lineresults[riff_number][string_line] = {'linestr':linestr.rstrip(), 'commonchar':commonchar, 'string_line':string_line, 'riff_name':riff_name, 'riff_number':riff_number}
#lineresults[riff_number] = {'linestr':linestr.rstrip(), 'lineno':lineno, 'string_line':string_line, 'riff_name':riff_name, 'riff_number':riff_number}
#print 'done: ' + str(len(lineresults)) + ' lines'
#pp.pprint(lineresults)
linelengths = {}
# get longest line ?
for rnum in lineresults:
linelengths[rnum] = 999
for ln in lineresults[rnum]:
if ln > 0:
if len(lineresults[rnum][ln]['linestr']) < linelengths[rnum]:
linelengths[rnum] = len(lineresults[rnum][ln]['linestr'])
if linelengths[rnum] == 999:
linelengths[rnum] = 0
result_dict = {}
for rnum in lineresults:
result_dict[rnum] = {}
raw_lines = ''
try:
raw_lines += str(lineresults[rnum][None]['linestr']) + "\n"
riff_name = str(lineresults[rnum][None]['linestr'])
except:
pass
try:
raw_lines += str(lineresults[rnum][0]['linestr']) + "\n"
except:
pass
try:
raw_lines += str(lineresults[rnum][1]['linestr']) + "\n"
except:
pass
try:
raw_lines += str(lineresults[rnum][2]['linestr']) + "\n"
except:
pass
try:
raw_lines += str(lineresults[rnum][3]['linestr']) + "\n"
except:
pass
try:
raw_lines += str(lineresults[rnum][4]['linestr']) + "\n"
except:
pass
try:
raw_lines += str(lineresults[rnum][5]['linestr']) + "\n"
except:
pass
try:
raw_lines += str(lineresults[rnum][6]['linestr']) + "\n"
except:
pass
result_dict[rnum]['raw_lines'] = raw_lines
# alphabetize fret nums
for i in lineresults[rnum]:
lineresults[rnum][i]['linestr_a'] = AlphabatizeFrets(lineresults[rnum][i]['linestr'])
s = ''
for column in range(linelengths[rnum]):
try:
# first attempt at simple PM recording..
try:
##print lineresults[rnum][6]['linestr'][column],
if lineresults[rnum][0]['linestr_a'][column] <> ' ':
s += '#'
else:
s += '0' # record nothing?
except:
##print '?',
s += '0'
try:
##print lineresults[rnum][6]['linestr'][column],
s += lineresults[rnum][6]['linestr_a'][column].replace(' ','-')
except:
##print '?',
s += '?'
try:
##print lineresults[rnum][5]['linestr'][column],
s += lineresults[rnum][5]['linestr_a'][column].replace(' ','-')
except:
##print '?',
s += '?'
try:
##print lineresults[rnum][4]['linestr'][column],
s += lineresults[rnum][4]['linestr_a'][column].replace(' ','-')
except:
##print '?',
s += '?'
try:
##print lineresults[rnum][3]['linestr'][column],
s += lineresults[rnum][3]['linestr_a'][column].replace(' ','-')
except:
##print '?',
s += '?'
try:
##print lineresults[rnum][2]['linestr'][column],
s += lineresults[rnum][2]['linestr_a'][column].replace(' ','-')
except:
##print '?',
s += '?'
try:
##print lineresults[rnum][1]['linestr'][column],
s += lineresults[rnum][1]['linestr_a'][column].replace(' ','-')
###sz = lineresults[rnum][1]['linestr_a'][column].replace(' ','-')
except:
##print '?',
s += '?'
#print ',',
s += ' '
#print s,
except:
pass #test
#changing some chars for a test indexing run
# constructing the "LONG CODE"
#print s # original s code
# check first "note" for bar notes
if ("##" in s[:8] or "B" in s[:8] or "E" in s[:8] or "A" in s[:8] or "?" in s[:8] or "||" in s[:8] or "::" in s[:8]) and "-" not in s[:8]:
s = s[8:]
if ("##" in s[:8] or "B" in s[:8] or "E" in s[:8] or "A" in s[:8] or "?" in s[:8] or "||" in s[:8] or "::" in s[:8]) and "-" not in s[:8]:
s = s[8:]
# check late "note" for bar notes
if ("##" in s[-8:] or "E" in s[-8:] or "A" in s[-8:] or "?" in s[-8:] or "||" in s[-8:]) and "-" not in s[-8:]:
s = s[:-8]
if ("##" in s[-8:] or "E" in s[-8:] or "A" in s[-8:] or "?" in s[-8:] or "||" in s[-8:]) and "-" not in s[-8:]:
s = s[:-8]
#s = s.replace('0EADGBE','').replace('0||||||','').replace('0::::::','')
#s = s.replace('|||','')
s = s.replace('0||||||','|') # riff bar seperators
s = s.replace('#||||||','|') # riff bar seperators
s = s.replace('?','-') # temp - work on it later (mark out missing tabbed strings)
if ("| " in s[:2]):
s = s[2:]
# now to change LONG CODE to SHORT CODE
long_code = s
long_code_list = long_code.split()
short_code = ''
for w in long_code_list:
#print w
if w == '|':
w = '|'
ww = '|'
elif w == '0------':
w = '.'
ww = '.'
else:
wd = {}
cnt = 0
cntf= 0
for l in w:
if l == '#' or l == '0' or l == '-' or l == '/' or l == '(' or l == ')' or l == '\\':
wd[cnt] = str(l)
else:
wd[cnt] = str(7-cnt)+str(l)
cnt = cnt+1
#elif w[0:1] in [a-z]:
# print 'tt'
#pp.pprint(wd)
ww = ''
for i in range(0,7):
try: # ? changed last minute
ww += wd[i]
except:
pass
#short_code += str(w)+' '
wdee = str(ww)
wdee = wdee.replace('0-----','')
wdee = wdee.replace('0----','')
wdee = wdee.replace('0---','')
wdee = wdee.replace('0--','')
wdee = wdee.replace('0-','')
wdee = wdee.replace('0','')
wdee = wdee.replace('#-----','*')
wdee = wdee.replace('#----','*')
wdee = wdee.replace('#---','*')
wdee = wdee.replace('#--','*')
wdee = wdee.replace('#-','*')
wdee = wdee.replace('#','*')
if wdee[-5:] == '-----':
wdee = wdee[:-5]
elif wdee[-4:] == '----':
wdee = wdee[:-4]
elif wdee[-3:] == '---':
wdee = wdee[:-3]
elif wdee[-2:] == '--':
wdee = wdee[:-2]
elif wdee[-1:] == '-':
wdee = wdee[:-1]
if "H" in wdee:
wdee = '>'
if "P" in wdee:
wdee = '<'
short_code += str(wdee)+' '
result_dict[rnum]['short_code'] = short_code
result_dict[rnum]['long_code'] = long_code
result_dict[rnum]['riff_name'] = riff_name
#return short_code
return result_dict
Text parsing from hell!
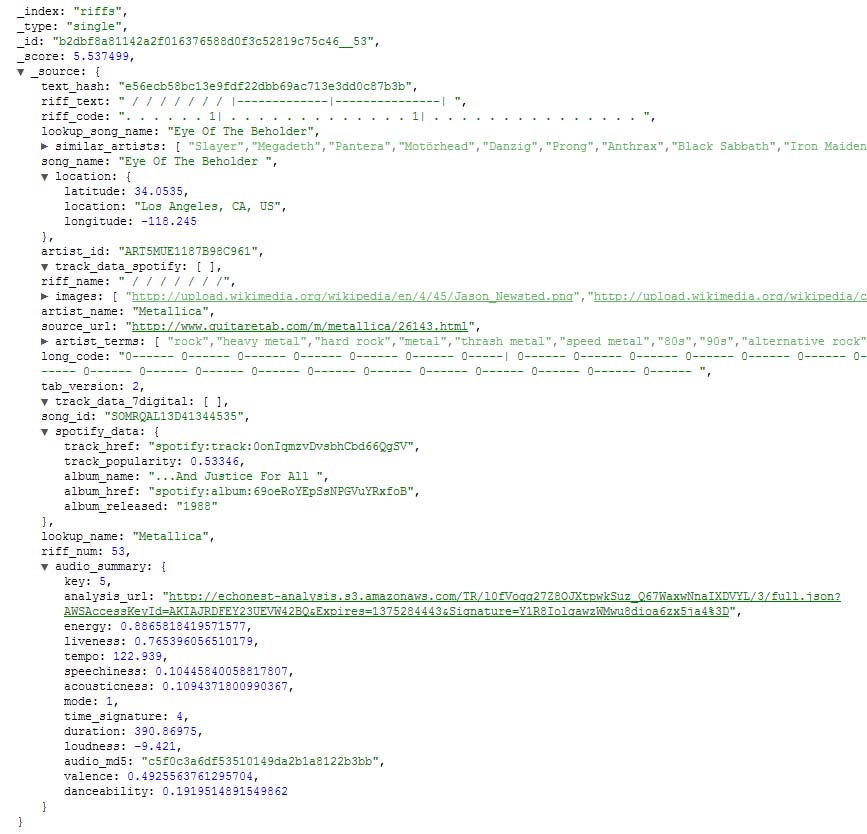
Anyways, that function is part of the module that I use to read the tab file into a JSON format that I can then insert into my "riff" ElasticSearch index - that is, of course, AFTER I pull the raw tab out of my "scraping" index. :)
Note: I'm using the amazing Requests module instead of a specific ES python module.
# prototype [riffbank / riffwords / riffml / riffql / riffjson] "encoder" script
# 7/3/2013
import requests, pprint, json, urllib
import time, os, string, sys, time, collections, hashlib
import riff_coder # custom
from random import choice
pp = pprint.PrettyPrinter(indent=3)
# get a random ES box each time
es_boxes = ['192.168.xxx.234','192.168.xxx.115','192.168.xxx.47','192.168.xxx.241','192.168.xxx.191','localhost']
payload = { 'query': { 'bool': { 'must': [ { 'match_all': { } } ], 'must_not': [ { 'term': { 'incoming.riff_indexed': 3 } } ], 'should': [ ] } } }
rrr = requests.get("http://localhost:9200/scraper/incoming/_search?from=0&size=5000", data=json.dumps(payload))
resp = rrr.json
rr = resp()
for i in rr['hits']['hits']:
print i['_id']
#pp.pprint(i)
es_box = choice(es_boxes)
x = i['_source']['raw_text'].splitlines(True)
riff_coder_dict = riff_coder.GenerateRiffCodeFromText(x)
#for each in riff_Coder_dict, insert ALL above fields plus rnum, raw_riff, short_code (no need for long code)
#then update scraper record as riff_indexed
print '----------------',i['_source']['artist_name'],' - ',i['_source']['song_name'],'---------------- ',es_box
#pp.pprint(riff_coder_dict)
try:
spotify_album_released = i['_source']['spotify_album_released']
spotify_album_href = i['_source']['spotify_album_href']
spotify_album_name = i['_source']['spotify_album_name']
spotify_track_href = i['_source']['spotify_track_href']
spotify_track_popularity = i['_source']['spotify_track_popularity']
except:
spotify_album_released = ''
spotify_album_href = ''
spotify_album_name = ''
spotify_track_href = ''
spotify_track_popularity = ''
try:
tabversion = i['_source']['tab_version']
except:
tabversion = 0
for r in riff_coder_dict:
url_hash = hashlib.sha1(i['_source']['source_url']).hexdigest()+'__'+str(r) # add domain of URL?
payload = { 'artist_id':i['_source']['artist_id'], \
'artist_name':i['_source']['artist_name'], \
'artist_terms':i['_source']['artist_terms'], \
'audio_summary':i['_source']['audio_summary'], \
'images':i['_source']['images'], \
'location':i['_source']['location'], \
'lookup_name':i['_source']['lookup_name'], \
'lookup_song_name':i['_source']['lookup_song_name'], \
'riff_num':r, \
'riff_name':riff_coder_dict[r]['riff_name'], \
'riff_code':riff_coder_dict[r]['short_code'], \
'riff_text':riff_coder_dict[r]['raw_lines'], \
'long_code':riff_coder_dict[r]['long_code'], \
'similar_artists':i['_source']['similar_artists'], \
'song_id':i['_source']['song_id'], \
'song_name':i['_source']['song_name'], \
'source_url':i['_source']['source_url'], \
'tab_version':tabversion, \
'text_hash':hashlib.sha1(i['_source']['raw_text']).hexdigest(), \
'track_data_7digital':i['_source']['track_data_7digital'], \
'track_data_spotify':i['_source']['track_data_spotify'], \
'spotify_data': { 'album_released':spotify_album_released, \
'album_href':spotify_album_href, \
'album_name':spotify_album_name, \
'track_href':spotify_track_href, \
'track_popularity':spotify_track_popularity } }
inr = requests.put("http://"+es_box+":9200/riffs/single/"+str(url_hash), data=json.dumps(payload)) # no need for response
print inr.text
print '----------------',i['_source']['artist_name'],' - ',i['_source']['song_name'],'----------------'
updpayload = { 'script': { "script" : "ctx._source.riff_indexed = 3" } }
upd = requests.post("http://"+es_box+":9200/scraper/incoming/"+i['_id']+"/_update", data=json.dumps(updpayload))
print upd.text
print ''
print ''
So now I've got each tab file (song) split into many "riff-based" JSON documents in my ElasticSearch system... (with a lot of extra meta-data picked up along the way - I'll write another post on searching Spotify and Echonest)
What's next? Getting it OUT in a meaningful way...
 Follow me on Twitter!
http://twitter.com/ryrobes
Follow me on Twitter!
http://twitter.com/ryrobes
 Facebook? Why Not!
http://facebook.com/ryrobes
Facebook? Why Not!
http://facebook.com/ryrobes